
LongRAG: A Dual-Perspective Retrieval-Augmented Generation Paradigm for Long-Context Question Answering
论文名: 长文本RAG:LongRAG双视角检索增强生成范式;
论文地址: http://arxiv.org/abs/2410.18050
代码地址: https://github.com/QingFei1/LongRAG
Abs
这篇论文提出了一种新的方法LongRAG,旨在通过长上下文问答(Long-Context Question Answering,LCQA)任务提升检索增强生成(RAG)模型的表现。该方法采用双视角的方式,通过引入全局信息提取器和基于链式推理(CoT)的过滤器来解决现有RAG方法中处理长文本的局限性。实验结果表明,LongRAG在多个多跳数据集上显著优于长上下文LLMs和先进的RAG方法。

1. Introduction
现象:长上下文问答(LCQA)任务要求在包含大量信息的长文本中进行复杂推理,以回答特定问题。然而,现有的长上下文LLMs和检索增强生成(RAG)模型在处理长文本时常遇到信息丢失的现象,特别是在文本中间部分关键信息容易被忽略,这一问题被称为“中间信息丢失(lost in the middle)”现象。
原因:长文本的处理需要有效的上下文保持和信息提取能力,但传统的RAG方法将长文本分块,这会破坏上下文的完整性。此外,模型在长文本中的检索结果质量不稳定,难以在多轮推理中准确识别和保留关键信息,导致最终生成的答案质量较差。
优点:本文提出的 LongRAG 方法通过引入双视角的RAG范式来解决这些问题。其优势在于:
- 全局信息提取器:通过提取全局语义信息,LongRAG能够保留长文本中的关键信息。
- CoT引导的过滤器:利用链式推理(CoT)机制过滤无关信息,使得模型可以更有效地从全局线索中找到答案。
- 模块化设计:LongRAG采用可插拔的模块设计,适应性强,可以应用于不同领域。
缺点:尽管LongRAG具备显著优势,但也存在一些局限性:
- 查询生成的预算限制:生成高质量的用户查询需要大量计算资源,且实际应用中可能面临有限预算的问题。
- 查询分布的现实性不足:模拟查询可能难以完全反映真实用户查询的复杂性和多样性,需进一步改进以提升应用效果。

1.1. lost in middle
Lost in the Middle 问题是一种在长上下文文本处理任务中经常出现的现象,尤其是在长上下文问答(Long-context Question Answering, LCQA)或长文本摘要生成任务中。该问题指的是,当模型处理长文本时,位于文本中间的关键信息可能会被忽略或处理不当,从而导致信息丢失和模型生成结果的质量下降。
1.1.1. 现象
在长文本中,信息通常分布在文本的开头、中间和结尾。然而,许多大语言模型(LLMs)在处理长文本时,对文本中间的内容的关注度较低,这就造成了“中间信息丢失”或“lost in the middle”现象。其具体表现包括:
- 缺少关键信息:模型的输出中缺乏原文中间部分的关键信息。
- 偏重文本开头和结尾:模型往往在开头和结尾片段的表现较好,而对中间内容的捕捉和理解不够。
- 上下文断裂:由于忽略了中间部分的内容,模型的输出可能缺乏逻辑连贯性,影响了最终回答或摘要的完整性和准确性。
1.1.2. 原因
造成Lost in the Middle问题的原因主要有以下几点:
- 上下文窗口限制:大多数LLMs的上下文窗口长度有限,通常只能一次性处理一定长度的文本。因此,超出窗口长度的内容可能会被截断或忽略,尤其是位于中间的内容。
- 注意力机制的局限性:基于 Transformer 架构的模型会对输入内容分配不同的注意力权重,开头和结尾的内容往往获得更高的权重,而中间内容的注意力权重可能较低,导致对中间内容的关注度不足。
- 信息的渐进丢失:在长文本中,模型逐步累积信息,并且会在处理过程中逐渐忽略之前的内容。当处理到中间段落时,模型可能已经“忘记”了前面的部分,使得对中间内容的理解不到位。
- 分块策略:许多模型将长文本分成若干片段处理,而分块通常是顺序或根据主题分割,难以在中间片段保持与全局的逻辑关联,从而导致信息脱节。
1.1.3. 解决方案
针对 Lost in the Middle 问题,研究人员提出了多种改进方法来确保中间内容的关键信息不会被忽略:
- 增大上下文窗口:使用更大的上下文窗口,以覆盖更多的文本内容,减少对文本中间部分的忽略。
- 两种解决办法:
- 用于训练或微调长上下文的方法(表现出更好的性能,但需要更高的训练和数据成本)
- 非微调方法包括基于受限注意力的方法以及上下文压缩方法(允许即插即用和低成本扩展大型语言模型)
- 两种解决办法:
- 层次化注意力机制:在模型中引入层次化的注意力机制,分层次地处理文本的不同部分,从而增强对中间内容的捕捉。
- 分段策略与拼接:将长文本分成多个独立的段落,分别进行处理后拼接,确保模型能够逐段理解文本中的细节。
- 全局信息提取器:如 LongRAG 中引入的全局信息提取器,旨在从文本全局视角提取关键内容,帮助模型在处理过程中始终保留对中间信息的关注。
1.2. Incomplete Key Information
Incomplete Key Information 问题,主要出现在 LCQA 任务中,当模型在处理包含大量信息的长文本时,会出现关键信息丢失的现象。模型在这些长文本中无法有效识别或保留完整的关键信息,导致生成的答案不准确或缺乏关键细节。
1.2.1. 现象
在长文本中,信息通常分散在多个段落、章节或文本片段中。模型在读取和处理长文本时,可能只聚焦在特定片段的内容上,忽略了其他与问题相关的关键信息,尤其是当这些关键信息嵌入在文本中间部分时。这种信息缺失通常表现为以下几种情况:
- 答案不完整:模型生成的答案缺乏关键细节,导致回答不准确或缺少解释。
- 语义不连贯:由于关键信息缺失,模型的输出可能语义不连贯,难以准确表达原文内容。
- 多次跳跃:在多跳问答任务中,模型难以识别多个信息源之间的关联,导致推理链不完整。
1.2.2. 原因
Incomplete Key Information 问题的成因可以归结为以下几点:
- 上下文窗口限制:大多数长上下文模型(如 LLMs)的输入长度有限,无法一次性处理整个长文本,导致部分关键信息被截断。
- 信息密度不均:长文本往往包含许多不相关的信息,而模型难以区分与问题高度相关的内容和不相关的内容,导致关键信息被“噪音”掩盖。
- 分块策略破坏了文本连贯性:传统的检索增强生成(RAG)方法依赖于分块策略,将长文本拆分成若干段落或文本片段。但分块会破坏原文的逻辑连贯性,使得模型难以捕捉上下文间的关联信息。
- 查询生成的局限性:模拟查询生成无法完全反映用户的真实需求,生成的查询可能过于简单或片面,导致检索的片段缺乏必要的关键信息。
1.2.3. 解决思路
为了应对Incomplete Key Information问题,研究者们提出了多种改进策略,例如LongRAG方法中的双视角RAG范式:
- 全局信息提取:通过添加全局信息提取器,保留文本中的关键信息并保持其连贯性,以确保模型在生成答案时不遗漏关键细节。
- 链式推理(CoT)过滤:通过链式推理机制,引导模型进行多轮推理,从而区分出与问题相关的关键信息,提高信息提取的准确性。
- 动态查询生成:根据长文本内容动态生成查询,优化检索到的文本片段的质量,从而提升回答的完整性。
-
传统
RAG在长上下文问答(LCQA)任务中存在两大局限性:- 分块策略破坏全局信息:RAG的分块策略会打断长文档中的上下文结构和背景信息(全局信息)。一些分块可能包含不完整的信息,导致 LLMs 依赖无关的上下文或回退到其内部参数化知识,从而可能导致不准确的响应。
- 低证据密度导致检索质量差:长文档中的低证据密度会导致检索到的分块质量低下。大量的噪声会影响LLMs准确识别关键信息(事实细节),从而导致检索到的低质量分块,最终导致错误的答案。
2. Method

2.1. Task Definition
3.1 任务定义
LongRAG 系统扩展了基础的 RAG 结构,包含一个检索器 R 和生成器 G,并加入了长上下文提取器 E 和链式推理过滤器 F,用于从长文档中提取关键信息并过滤无关内容。具体步骤如下:
- 给定问题 q \in Q 和长文档库 C,系统通过检索器 R 检索出前 k 个最相关的文本片段 p_c \in P_c。
- 这些片段 p_c 是由原始长段落 p \in P 分割得到的。
- 提取器 E 从 p 中提取全局信息 I_g,过滤器 F 从 p_c 中识别出包含事实细节的信息 I_d。
- 生成器 G 将结合 I_g 和 I_d 生成问题的最终答案。
在此,P 表示长文档中的所有段落,包含与问题相关的支持段落 P_s 和分散段落 P_d,用于训练模型。
2.2. Fine-Tuning Data Construction
LongRAG 系统构建了一个高质量的指令跟随数据集 —— LRGinstruction,用于监督微调以增强系统的指令跟随能力和长上下文理解能力。
-
数据来源选择:从多跳推理数据集(如HotpotQA、2WikiMultiHopQA、MusiQue)和长上下文数据集QASPER中选取训练集数据,这些数据集的复杂性和长上下文特性能够帮助系统学习更精细的推理能力和长文本处理风格。
-
自动化数据构建管道:利用大语言模型 ChatGLM3-32B-128k 生成数据集,通过自动化流程生成高质量的数据,用于微调和训练模型。
-
数据类型:
- 长上下文提取数据:用于增强模型对长文本全局信息的提取能力。给定问题和支持段落,模型输出回答问题所需的所有相关信息。
- CoT(Chain of Thought)指导数据:使用思维链方法指导模型在每个段落中识别关键线索,增强模型的推理能力。
- 过滤数据:用于识别段落中包含的事实细节,帮助过滤无关内容,以提高模型对问题相关内容的识别能力。
- 任务导向数据:包含原始数据集中的问答对,并经过格式标准化,进一步提升模型的问答能力。
创新性与优点
- 高效性:通过使用高质量且精炼的训练数据,显著减少了数据需求,仅需约2600个样本即可在LCQA任务中取得良好表现。
- 多功能性:LRGinstruction数据集由多种数据类型构成,支持模型在长文本全局信息提取、推理链过滤、以及任务导向的问答生成等方面进行全面训练。
- 自动化构建:自动生成流程降低了人工标注的成本,并且可以轻松扩展至其他领域数据,实现高效的领域适应性训练
2.3. The LongRAG System
2.3.1. Hybrid Retriever
混合检索器首先针对给定问题召回 k 个文本片段,并对长文本 p 进行分割生成小片段 p_c,确保语义连续性。分段时,以句子为最小单位并使用滑动窗口添加上下文内容,以防止语义破损。最终,通过双编码器结构进行粗粒度检索,并用交叉编码器进行细粒度语义互动检索,从而实现高效的分层检索。
粗粒度检索可以快速覆盖大量相关文档,而细粒度检索则可以在粗粒度检索的基础上进一步捕捉文档中的深层语义关系。
2.3.2. LLM-augmented Information Extractor
信息提取器针对长上下文低证据密度的问题,采用映射策略将短片段 p_c 映射回其长文本 p。映射函数如下:
其中 k \leq k',每个 p 为最相似的上下文段落。提取器会将这些段落拼接并输入LLM的零样本上下文学习,提取全局信息 I_g:
这种方式有效扩展了检索到的片段的全局语境,使得模型可以更准确地生成含有背景和结构知识的答案

2.3.3. CoT-guided Filter
LongRAG系统引入了思维链(Chain of Thought, CoT)COT引导过滤器,以帮助多跳推理任务识别和过滤掉冗余或无用的信息片段 p_c,特别适用于复杂推理链和证据密度较低的长上下文。
CoT-guided Filter 采用两阶段策略,分为CoT指导阶段和过滤阶段:
-
CoT指导阶段:
- 系统首先生成一个思维链(CoT),用于构建全局推理路径,帮助分析问题所需的整体线索。该阶段生成的思维链 \text{CoT} 是基于问题 q 和检索到的所有文本片段 p_{c1}, p_{c2}, \dots, p_{ck} 生成的,公式表示如下:
其中,k 表示文本片段的数量,\text{prompt}_c(\cdot) 为CoT的提示模板。
-
过滤阶段:
- 在该阶段,思维链 \text{CoT} 为每个片段提供全局线索,引导LLM逐步聚焦于问题相关的知识。通过函数 V(q, p_c, \text{CoT}) 的二值标签评估,判定每个片段 p_c 是否支持回答问题 q:
(q,p_c,\text{CoT})=\begin{cases}\text{True,}&\text{if<support>}\\\text{False,}&\text{otherwise}\end{cases}- 所有被标记为"True"的片段构成包含事实信息的集合 I_d:
_d = \{ p_c \mid V(q, p_c, \text{CoT}) = \text{True} \}- 该过滤阶段通过精确过滤冗余的片段 p_c 并保留关键的事实信息,确保下游生成器得到低冗余的输入,提升回答的质量和准确性。

2.3.4. LLM-augmented Generator
在 LLM增强生成器模块中,LongRAG通过整合全局背景信息 I_g 和事实细节信息 I_d 生成最终答案。生成器接受来自前几层提取和过滤的信息,利用LLM进行答案生成,以提升答案的完整性和准确性。生成过程如下:
其中,\text{prompt}_g(\cdot) 为生成器的提示模板,I_g 表示通过LLM增强的信息提取器生成的全局信息,而 I_d 是经过 CoT-guided Filter 筛选的细节信息集合。生成器结合 I_g 和 I_d 生成答案 \alpha,从而实现基于全局和细节的双视角长文本回答。这一模块的设计确保了LLM可以从长文本中提取全面的背景信息和关键细节,提高生成答案的准确性和逻辑连贯性。

2.3.5. Instruction-Tuning
在 Instruction-Tuning 模块中,LongRAG利用高质量的指令跟随数据集LRGinstruction对系统进行微调,使其在指令跟随和长上下文处理上表现更优。
微调过程:
- 模型选择:选择最优的LLM(如ChatGLM、Qwen、Vicuna、Llama2和Llama3)进行微调。
- 数据集:微调使用了四种数据类型(包括长上下文提取数据、CoT指导数据、过滤数据和任务导向数据),确保模型在多层次任务中表现稳定。
- 优化方法:在训练过程中,使用DeepSpeed、ZeRO3、CPU offloading和Flash Attention等优化技术,在多块A100 GPU上进行训练。训练参数包括批次大小为8、梯度累积步数为12,总共进行3个epoch,以实现模型的充分训练。
这一模块通过高质量的指令微调,提高了模型在指令理解和长文本问题上的表现,使LongRAG系统能够更有效地处理复杂的长上下文问答任务。
3. Experiment
3.1. Experimental Setup
- 数据集与评估:选取了三个具有挑战性的多跳推理数据集——HotpotQA、2WikiMultiHopQA(2WikiMQA)和MusiQue。为了适配RAG任务,对数据进行了标准化处理,并以F1-score作为主要评估指标 。
- 对比基线与模型:基线模型包括长上下文LLM方法(如LongAlign和LongLoRA)、先进的RAG方法(如CFIC和CRAG),以及标准RAG(Vanilla RAG)模型。测试的LLM包括参数规模从小至大的多个模型,如ChatGLM3-6B、Qwen1.5-7B、Llama3-8B等
3.2. Overall Performance
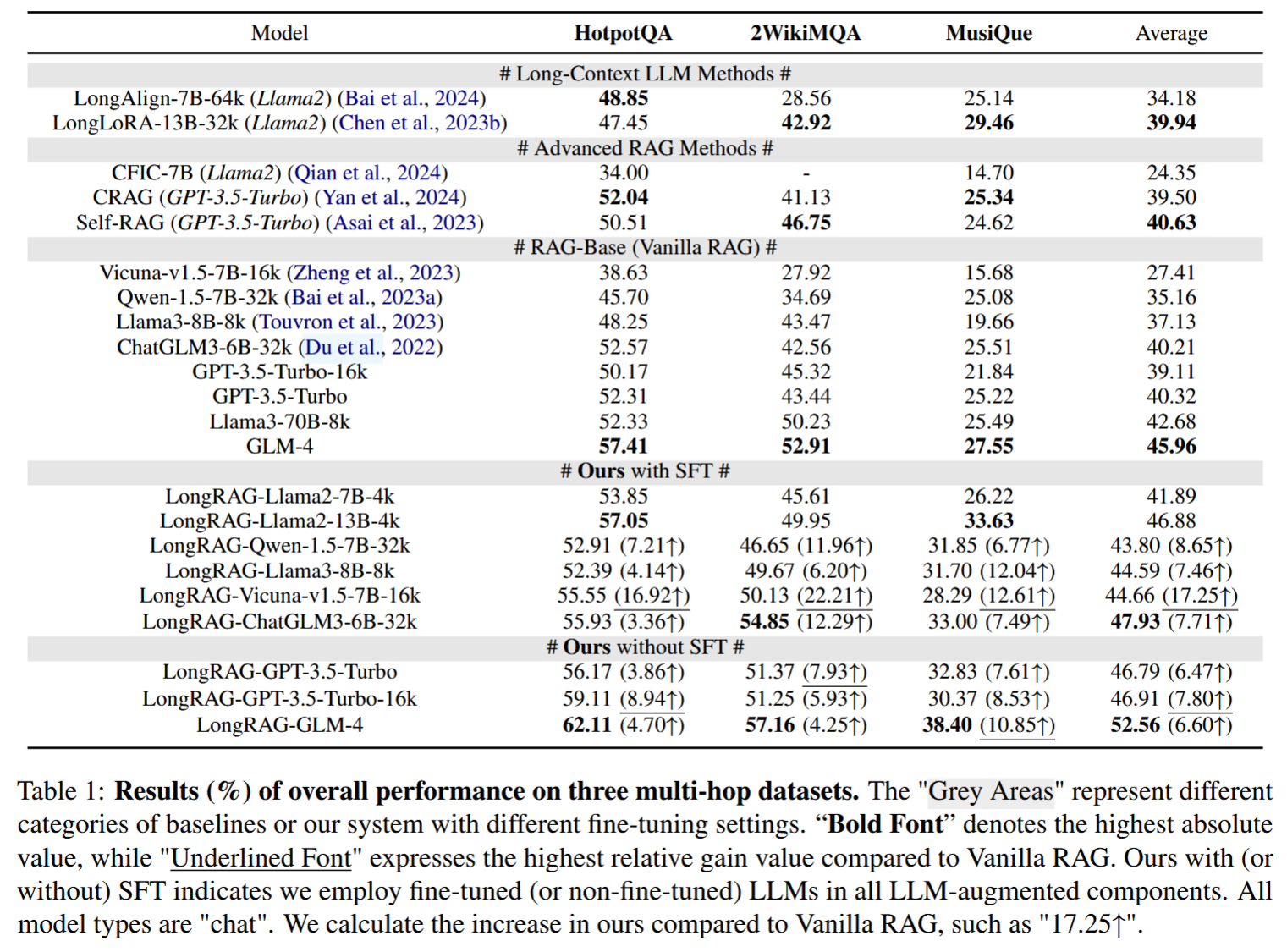
- vs. Long-Context LLM Methods
- LongRAG在所有数据集上均表现出色,尤其是使用微调的小尺寸LLM时,显著优于基线方法。
- 这是因为长上下文LLM常常忽略中间的关键事实细节,而LongRAG能够精确且稳健地感知这些细节
- vs. Other RAG
- 与先进RAG相比,LongRAG在三个数据集上的平均性能提高了6.16%。
- 与Vanilla RAG相比,所有LLM的应用均表现出显著提升(最高达17.25%)。
- 这是因为Vanilla RAG将长上下文分割成较小的语义单元,阻碍了下游生成器访问更连贯的长上下文背景和原始长上下文结构。
- Small-Size vs. Large-Size LLMs
- 无论使用微调的小尺寸还是非微调的大尺寸LLM,LongRAG在所有数据集上均表现优异。
- 特别是使用微调的ChatGLM3-6B-32k时,性能优于未微调的GPT-3.5-Turbo,证明了系统范式在分析和处理复杂长上下文方面的能力。
3.3. Ablation Study

消融研究显示了五种策略的结果,突出了信息提取器和CoT引导过滤器组件的有效性。具体来说:
- RAG-Long vs. RAG-Base:RAG-Long策略未能在性能上显著提升。
- Extractor vs. RAG-Long:提取器策略在所有三个数据集上均表现出显著提升,特别是在较大尺寸LLM上。
- Filter vs. RAG-Base:单独使用过滤器在少数情况下表现略有提升,但在大多数情况下,与提取器结合使用时效果更好。
- Extractor & Filter vs. Others:E&F策略在大多数情况下表现最佳,提供了更有用且简洁的信息集。
3.4 讨论
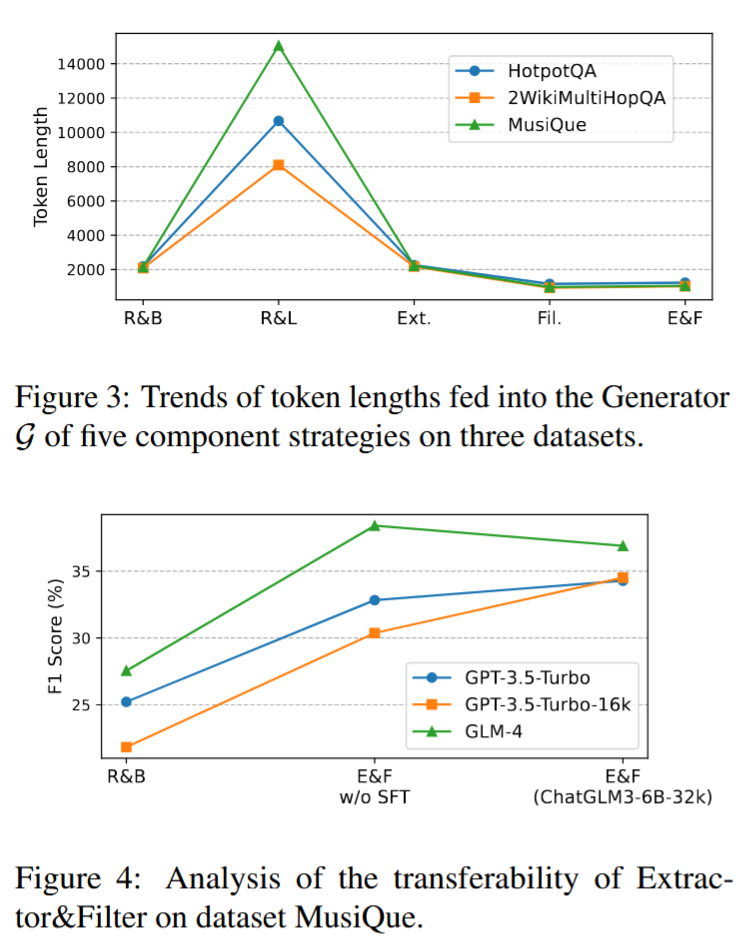
- 令牌长度趋势分析:图3显示了所有数据集上五个策略的令牌长度趋势。结果表明,E&F策略向生成器输入的令牌较少,但结果更优。
- 组件可转移性分析:图4显示了在MusiQue数据集上E&F组件的可转移性。结果表明,可以将昂贵的在线LLM替换为低成本的本地模型,同时保持优异的性能。
4. Conclusion
-
系统概述:LongRAG是一个高效、稳健的RAG(Retrieval-Augmented Generation)系统范式,专门用于增强长上下文问答(LCQA)任务中的RAG性能。该系统采用了双视角信息增强方式,解决了现有方法中存在的两个主要问题:
- 长上下文信息不完整:通过双视角的信息提取机制,LongRAG能够捕捉更全面的上下文信息。
- 噪声中识别事实信息的困难:利用链式推理过滤器(CoT-guided Filter),LongRAG能更精确地从大量噪声中识别关键事实信息。
-
实验验证:作者进行了多维度的实验,验证了LongRAG的优越性及其模块和微调策略的有效性。实验结果表明,LongRAG在不同的LLM模型下表现出色,显著优于传统长上下文LLMs、先进RAG方法和标准RAG(Vanilla RAG)。
-
系统优势:LongRAG采用了可插拔的组件设计,能够在小参数量LLMs上高效运行,减少了对昂贵在线API的依赖,提供了更经济的本地部署解决方案,其性能甚至优于GPT-3.5-Turbo。
-
数据构建管道:作者提供了一个自动化的指令数据微调管道,方便将LongRAG应用于其他特定领域的数据,提升了系统的适用性和扩展性。
局限性:
- 一次性检索依赖:LongRAG目前依赖于一次性检索,在此设定下,信息提取器和CoT引导过滤器的性能取决于单次检索到的文本片段质量。低质量的一次性检索可能会影响系统的整体性能。未来可以通过开发一种自适应的多轮检索策略,增强系统在不同检索条件下的适应性。
- 数据集注释偏差:尽管LongRAG使用了32B参数量的ChatGLM3模型生成高质量的微调数据集,但该规模的模型仍可能受到自生成数据集中固有的偏差影响。这种偏差可能会削弱微调模型在跨领域和多任务环境中的表现。未来工作可以在不同规模的LLMs生成的指令数据集上,进一步评估和改进系统在跨领域和多任务中的适应性。
评论区